Chap 1 Digital Systems and Information¶
约 2053 个字 9 行代码 预计阅读时间 10 分钟
信息表达 | Information Representation¶
现实世界中的信息往往是 连续(continuous) 的,但在人造物的世界中,大部分信息都是 离散(discrete) 的。
在电子信息系统中,信号分为 模拟信号(analog signal) 和 数字信号(digital signal) 两种。其中,在 数字信号(digital signal) 中又有多种表示方法,如今我们最常用的是 二进制(binary)。对应到电路层面,我们常常用 高电位(HIGH) 和 低电位(LOW) 来表征 1 和 0。
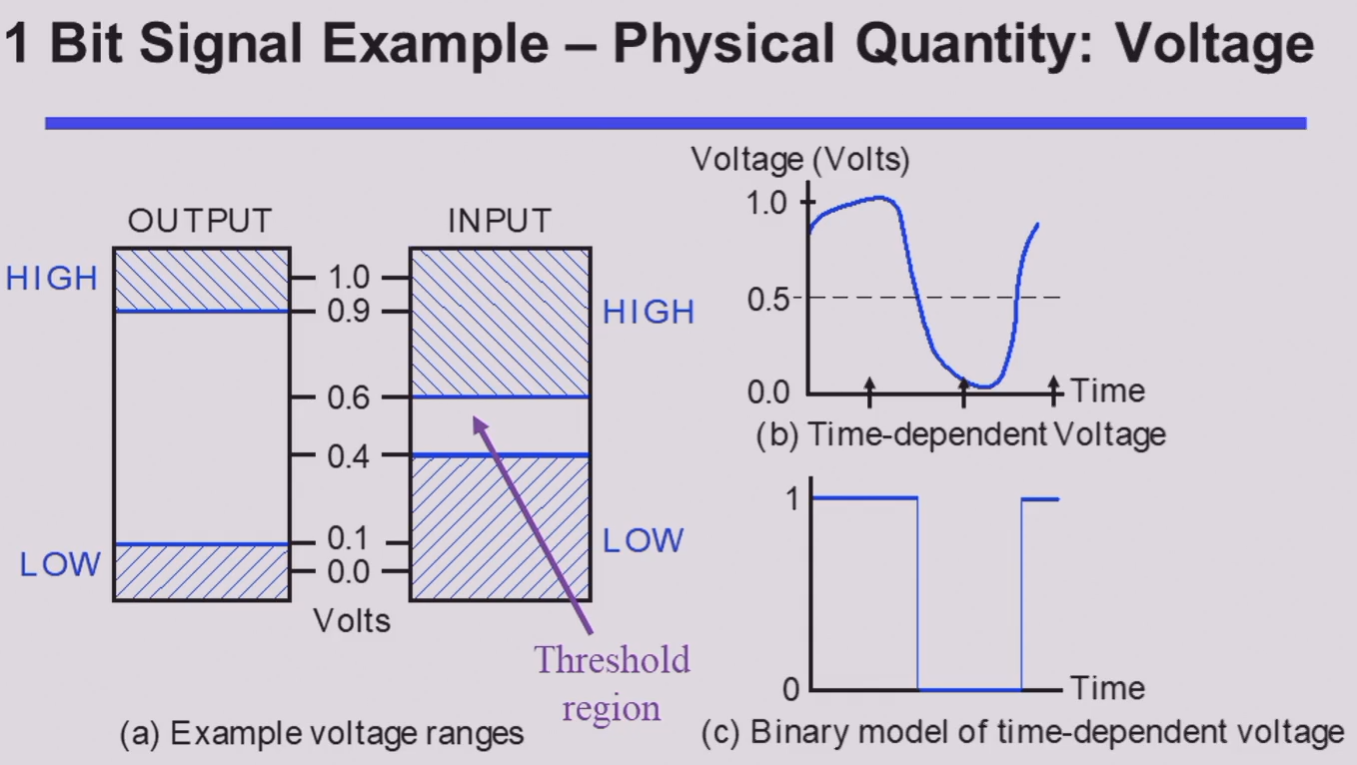
值得注意的是,在输入和输出中,高低电位的接受范围是不同的。可以发现,输入的判定范围比输出的判定范围大,即 宽进严出。其目的是为了进一步提高电路在噪音等异常影响下也能正常表现的能力。
| HIGH input | LOW input | HIGH output | LOW output |
|---|---|---|---|
| 0.6 ~ 1.1 | -0.1 ~ 0.4 | 0.9 ~ 1.1 | -0.1 ~ 0.1 |
或许你也已经注意到了,在图中,HIGH 的接受范围和 LOW 的接受范围之间还存在一段区域。落在这一部分的电平是 未定义(undefined) 的,也被称为是 浮动(floating) 的。如果输出的电平是在浮动区间的,那么其认定值将是随机的。
事实上,在信息的对应上,虽然将高低电平同 HIGH/LOW 联系是很自然的,但是将他们同 true/false 或者 1/0 联系其实并不唯一。但是在一般情况下(我们称之为 positive logic),我们都认为 HIGH ~ true ~ 1, LOW ~ false ~ 0。
可以发现,(b) 图中的模拟信号在经过我们的器件后,会被认为是 (c) 图所示的信号。而这些操作在硬件层面,我们通过 晶体管(transistors) 来实现。
这也牵扯到我们为什么最终使用二进制来表示信息。一方面是因为二值器件比较常见,亦即这里提到的晶体管;另外一方面是使用二进制可以降低电路成本。
计算机系统设计中的抽象层 | Abstraction Layers in Computer Systems Design¶
| 越上层抽象程度越高 |
|---|
| Algorithms |
| Programing Languages |
| Operating Systems |
| Instruction Set Architecture |
| Microarchitecture |
| Register Transfers |
| Logic Gates |
| Transistor Circuits |
数字系统 | Number Systems¶
首先需要涉及的问题是进制转换。
对于一个 \(r\) 进制数,它一般被写成这样:
而它对应的十进制真值为:
计算机领域常见的进制主要是 二进制(binary),八进制(octal),十进制(decimal) 和 十六进制(hexadecimal)。
其中二、八、十六进制之间的转换非常简单,存在多位到一位之间的无后效性映射,例如二进制转换到十六进制只需要将从低到高每四位转化成十六进制中的一位即可。
需要注意,由于二进制和十进制在零位上的权重相同,这意味着在整数部分,二进制和十进制是可以相互精准转化的(即最小精度是一致的,都是 1);然而该性质在小数部分并不成立(因为小数部分不存在“最小精度”一说),即十进制无法精准转化为二进制,但二进制可以转化为十进制。
算术运算 | Arithmetic Operations¶
这里涉及的主要是 加法(Addition)、减法(Subtraction)、乘法(Multiplication)。
整体流程和小学竖式加法是一致的。
二进制运算



编码 | Codes¶
二进制编码主要分为这么几种:
- Numeric
- 必须表达一定范围内的数字;
- 能够支持简单且普遍的计算;
- 和二进制数值本身有较大关联;
- Non-numeric
- 相对灵活,因为不需要适配普遍的运算法则;
- 灵活性指,保证编码映射关系是唯一的的情况下都可以称为合法编码;
- 和二进制数值本身未必有关系;
- 相对灵活,因为不需要适配普遍的运算法则;
独热码 & 独冷码¶
独热码(one-hot) 要求比特向量中只有一位是 1;对应的还有 独冷码(one-cold)。
使用这种编码的好处是,决定或改变状态机目前的状态的成本相对较低,容易设计也容易检测非法行为等。
但是相对应的,缺点是信息表示率较低,非法状态非常多而有效状态很少。
BCD 码¶
由于真实世界中大部分数据表述都是以十进制实现的,所以我们需要研究如何用二进制来表示十进制。
首先,一位二进制数能包含的信息是 1bit,也就是一个“真”或者一个“假”。我们称一个拥有 n 个元素的二进制向量为一个 n位二进制编码(n-bit binary code)。一个 n 位二进制数拥有 \(2^{n}\) 种可能的组合,因而可以表示 \(2^n\) 种信息。
而我们需要设计的编码系统,就是将我们需要的信息映射到这 \(2^n\) 个“空位”中。当然,当我们需要表示的信息数量并不是 2 的幂次时候,会出现一些 未分配(unassigned) 的比特组合。
而在这种编码中,最常用的就是 BCD码(binary-coded demical)。其核心思路就是,将十进制的每一位 分别 用 真值相等的 4 位二进制 表示,即 0 ~ 9 分别用 0000 ~ 1001 表示。
| Decimal Symbol |
BCD Digit |
|---|---|
0 |
0000 |
1 |
0001 |
2 |
0010 |
3 |
0011 |
4 |
0100 |
5 |
0101 |
6 |
0110 |
7 |
0111 |
8 |
1000 |
9 |
1001 |
eg
余三码¶
一种 BCD码 的改进是 余三码(Excess3)。其核心思路是在 BCD码的基础上,增加一个大小为 3 的偏移量。
| Decimal Symbol |
Excess3 Digit |
|---|---|
0 |
0011 |
1 |
0100 |
2 |
0101 |
3 |
0110 |
4 |
0111 |
5 |
1000 |
6 |
1001 |
7 |
1010 |
8 |
1011 |
9 |
1100 |
为什么是 3 呢?首先这个 3 来自于 \(\frac{16-10}{2}\),也就是 8421 码的容量减去我们需要表示的数字数量,再除以二。这样的好处是,十进制下能进位的两个数,在余三码下相加也刚好进位。
但是需要强调的一点是,编码和数值是存在区别的,虽然我们提到了余三码相加,但是编码做运算多数情况下是没有意义的。“运算”的主体更多是数值。
格雷码¶
此外,这里不得不提的另外一个编码是 格雷码(Gray Codes)。格雷码的特征,也是他的优点,就是相邻的两个数在二进制下的表示只差一位(当在占满时,对于整个编码序列,环状满足该条件)。
比如有如下应用:

以及在许多状态控制中都有着广泛的应用。
从笔试做题角度来说,格雷码最麻烦的其实是与十进制数的转换。(此处 @CSP-S2019-Day1-T1)
个人认为最好做的做法就是,假设我们要找的是第 k 个格雷码,则对应的格雷码为:
ASCII 码¶
字符编码所使用的一般是 ASCII 编码,由于 ASCII 已经是老生常谈了,所以这里不再展开。
奇偶校验位¶
信道编码与信源编码:
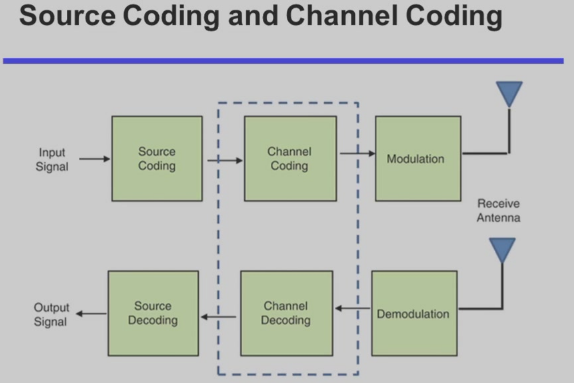
在信号传输过程中,可能由于环境干扰等原因,出现各种信号抖动,所以为了保证数据的可信度,我们需要一个错误检测机制。
一种常见的方法是 冗余(Redundancy),即加入一些额外的信息用以校验。
graph TD
A[Error Detection Techniques]
B[Single Parity Check]
C[Cyclic Redundancy Check]
D[Check Sum]
A-->B
A-->C
A-->D其中一种做法是引入 奇偶校验位(Parity Bit)。它分为 奇校验(Odd Parity) 和 偶校验(Even Parity)。分别通过引入额外的一位,来保证整个信息串中 1 的数量是奇数/偶数。
- 比如,如果我们采用偶校验,原始信息为
1101,其中有 3 个1,这时我们在后面再加上一个1,保证了整个信息串中有偶数个1;或者如果原始信息为1001,其中有 2 个1,这时我们则在后面加一个0。此时,如果传输过程中出现了问题,那么1的数量很可能变成了一个奇数,此时我们就知道,这个信息是不对的。
创建日期: 2024年1月13日 19:00:24